PHERAstar FSX
Powerful and most sensitive HTS plate reader


Dr. Ann Cathrin Volz is a trained nutritionist with deep expertise in cell biology, biomaterials and food science. She studied Molecular Nutritional Sciences at the University of Hohenheim, where she completed her PhD developing a serum-free in vitro model of adipose tissue. During her scientific training, she combined academic biochemistry with practical laboratory work in bioengineering. After completing her doctorate, she spent two years as a postdoctoral researcher at Reutlingen University, where she focused on transferring her knowledge of tissue engineering from biomedicine to the field of in vitro agriculture. In 2020 Ann-Cathrin joined BMG LABTECH as an Applications Specialist, where she authors application notes, conducts workshops, and supports scientific customers.
Nucleic acids
DNA interacts with other nucleic acids. DNA-DNA interactions play a vital role in a number of processes and are hypothesised to be key to large-scale chromosome organisation1. Looking at RNA, single-stranded RNA (ssRNA) can anneal to its double-stranded DNA template – co-transcriptionally or post-transcriptionally – creating an R-loop comprised of an RNA-DNA hybrid (RDH) duplex and a displaced single-stranded DNA (ssDNA). Roughly 60 % of human genes contain RDH-forming sequences, and they make up around 5 % of the mammalian genome, with functions in a variety of processes including transcription, replication, chromosome segregation, telomere regulation, DNA repair, and DNA methylation2.
Additionally, a substantial proportion of the human genome encodes non-coding RNAs (ncRNAs) instead of proteins. ncRNAs include microRNAs (miRNAs), small interfering RNAs (siRNAs), PIWI-interacting RNAs, and long non-coding RNAs (lncRNAs) – all of which play important roles in multiple biological processes, particularly epigenetic regulation3. Nuclear lncRNAs participate in chromatin organisation and transcriptional regulation and act as a structural scaffold to promote further interactions between proteins and nucleic acids4. There is also further evidence to suggest sequence-specific interactions of lncRNAs with DNA via triple-helix (triplex) formation, where DNA binds a third single-stranded nucleic acid in its major groove. Research has shown that lncRNA-DNA triplexes recruit protein complexes to specific genomic regions and regulate gene expression, controlling transcription through the recruitment of coactivator or corepressor proteins.
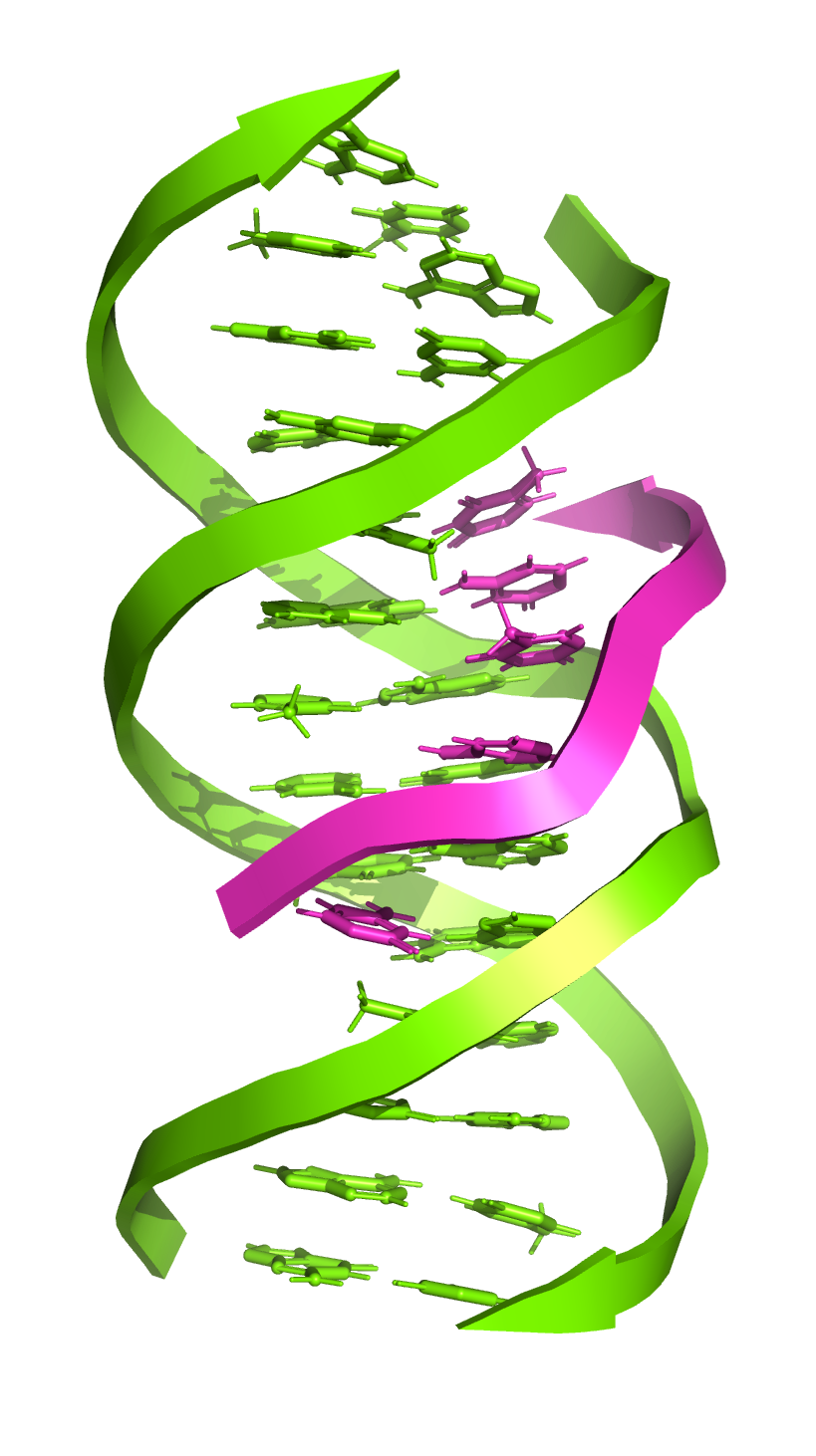
As for many other downstream methods, accurate DNA quantification is an important prerequisite for interaction studies.
For instance, a nucleolar lncRNA can form a triplex with a ribosomal DNA promoter that is then recognised by the DNA methyltransferase DNMT3B, which methylates rDNA promoters and represses rDNA transcription. Further studies have also demonstrated the ability of specific proteins to interact with triplexes in vivo, for example, helicases such as RecQ can unwind triplex structures, signifying a potential regulatory role of triplexes5.
Proteins
Protein-DNA interactions are also fundamental to almost all biological processes in eukaryotes, from controlling the organisation of DNA and chromatin to transcription, DNA repair, and replication. Understanding how proteins interact with DNA, what proteins are interacting, and what nucleic acid sequences are involved, is absolutely key to understanding how these complexes affect biological pathways. DNA-binding proteins include structural molecules, transcription factors, polymerases, nucleases, and proteins that help repair breaks in the DNA double helix such as PARP1 highlighted in the application note “PARP1 and PARP1-HPF1 Complex association with inhibitors assessed using kinetic fluorescence polarization measurements”. DNA-histone interactions are especially important, playing a role in chromatin structure and gene regulation, helping to condense and structure DNA. The human genome contains approximately three billion base pairs, meaning that each individual cell contains around two metres of DNA. Without proteins and other molecules to package this DNA, there is no way it could fit in the human body! The positively-charged histones strongly bind to negatively-charged DNA to form nucleosome complexes that fold into chromatin fibers. These are further compressed and folded, before being tightly coiled into a pair of chromatids that form a chromosome. DNA-histone interactions can also be modified by acetylation or methylation, where acetylation loosens the winding of DNA, increasing access to allow transcription, and methylation prevents transcription factors from binding, leading to gene silencing6.
DNA-protein interactions are mediated by either direct contact between the base pairs of DNA and specific amino acids in the protein structure, or indirect contact facilitated predominantly by water molecules and conformational changes in the DNA structure. Proteins bind with DNA through electrostatic interactions (salt bridges), dipolar interactions (hydrogen bonding), entropic effects (hydrophobic interactions) and dispersion forces (base stacking), determining whether a protein binds in a tight, sequence-specific manner or through a loose, non-specific interaction7. It is also possible to increase the affinity and specificity of a particular protein-nucleic acid interaction through multi-protein complex formation or oligomerisation. During binding, both protein and DNA conformation can be altered, which can enhance the binding of other proteins. This includes changes in protein side-chain location and local refolding, as well as bending of the DNA backbone or local untwisting of the helix.
Specific DNA interactions
Double-stranded DNA has a highly negatively-charged sugar-phosphate backbone, with a core of stacked base pairs whose edges are exposed in the major and minor grooves. Every DNA sequence has a unique chemical signature characterised by the functional groups on each base. Proteins are able to recognise this chemical pattern, along with sequence-dependent variations in DNA structure and flexibility for binding. Most sequence-specific DNA binding proteins recognise and bind to their target DNA sequence with a high affinity, using structural domains to make sequence-specific contact with the DNA bases in the major groove. While there is remarkable structural diversity in DNA binding folds, common binding motifs in the genome can be observed8.
The most common DNA binding domains include:
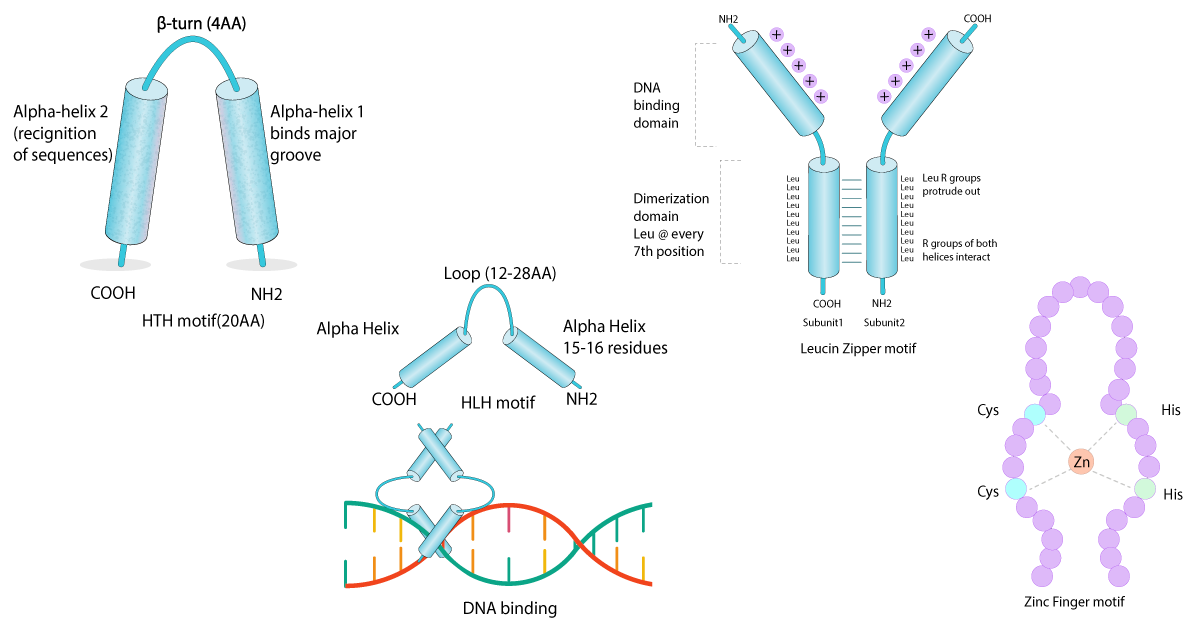
Non-specific DNA interactions
Non-specific DNA interactions are much weaker. They are primarily electrostatic in nature and occur between a protein and the negatively charged DNA backbone. For this interaction to occur, the protein must have positively charged amino acids on its surface, in positions that are complementary to the arrangement of phosphates either along the DNA backbone or across the minor and major grooves.
Proteins that interact in this way include:
A number of laboratory techniques exist to study DNA interactions, including electrophoretic mobility shift assays (EMSAs) and chromatin immunoprecipitations (ChIPs). However, these methods are often laborious or limited to specific targets. Instead, binding is more commonly being studied by observing changes in fluorescence intensity emission and anisotropy – partially due to the range of fluorophores available, as well as the lower cost of commercial syntheses. Fluorescence methods are also popular because they are highly suited for interactions with dissociation constants in the range of 10-4-10-8 M, where many protein-DNA dissociation constants lie.
Fluorescence quenching
Fluorescence quenching studies the decrease in fluorescence intensity in a sample due to interactions between a fluorophore and quencher molecule. The quencher absorbs the emission of a fluorophore, if both are found in close proximity. Fluorescence quenching is popular for DNA interaction studies, as oligonucleotides are easily and cost-effectively labelled with a fluorophore or quencher. Combining a fluorescently labelled oligonucleotide with a quencher-labelled protein reports on interaction between DNA and protein. Labelling two DNA strands, one with a fluorophore, the other with a quencher allows to monitor unwinding of a double-strand9 as discussed in the application note “Molecular beacon based helicase assays”.
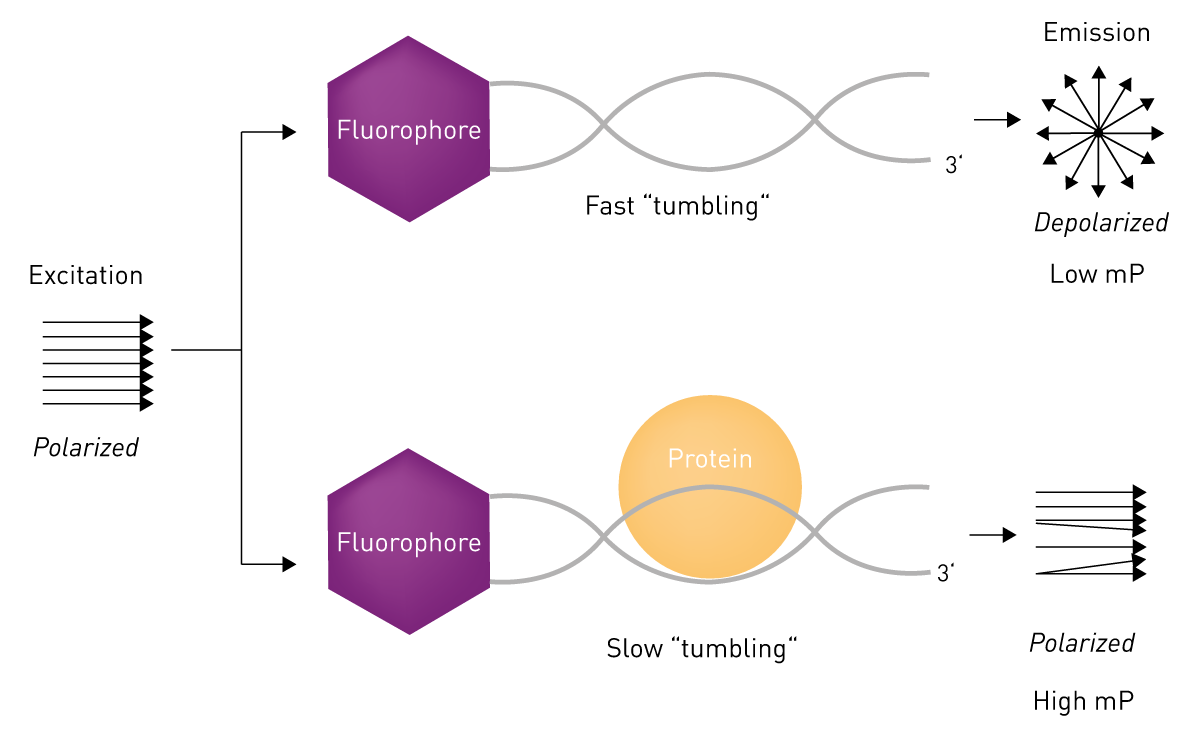
Fluorescence polarisation
Fluorescence anisotropy is the property of large fluorescent molecules to retain the polarisation of the excitation light due to a low tumbling rate in solution. The method is a popular true‐equilibrium, real‐time technique that analyses the binding of a protein to a fluorophore-labelled oligonucleotide. It is ideal for studying protein-DNA interactions, as the resulting complex is larger and tumbles more slowly while the unbound oligo tumbles more quickly and has a lower fluorescence polarisation. Fluorescence polarisation enables affinities to be measured in solution without requiring a step to separate free and bound oligo, and can be used to collect data over the course of a binding reaction10.
In the application note “High-throughput protein-DNA measurement using fluorescence anisotropy”, the effect of modified nucleotides on the recognition of DNA by the tumour suppressor p53 is analysed using fluorescence anisotropy titrations.
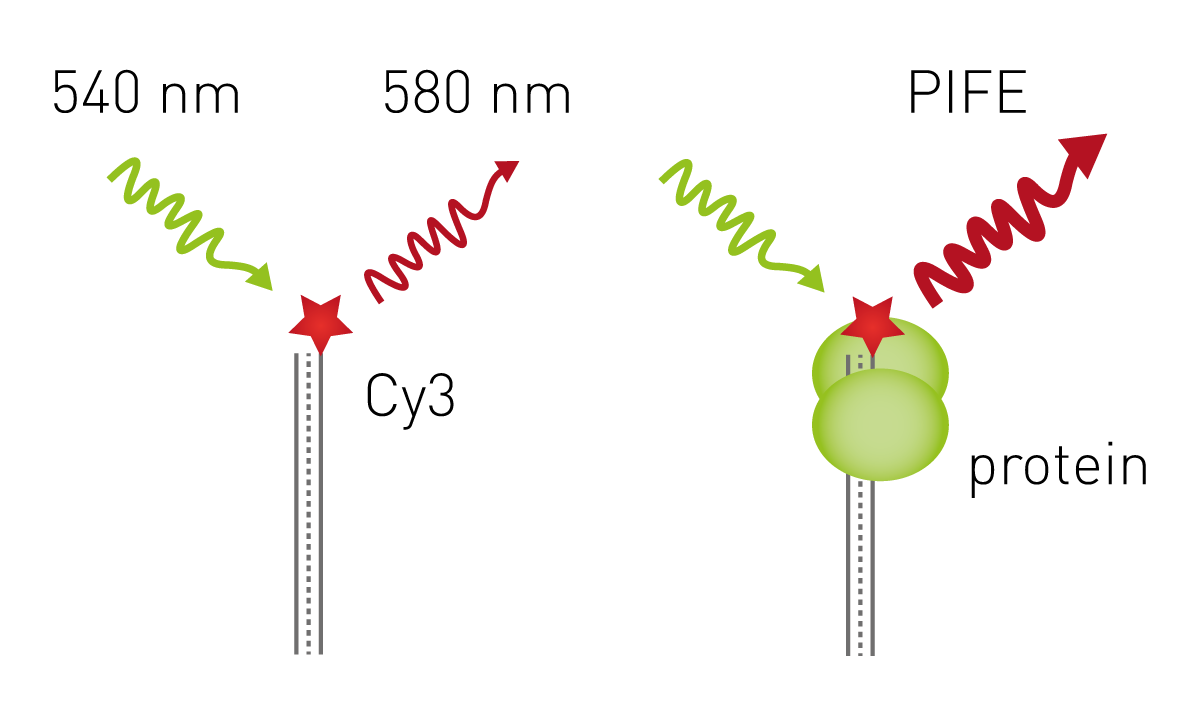
PIFE
Novel approaches are constantly in development, and this includes the simple and cost-effective Protein-Induced Fluorescence Enhancement (PIFE) assay. PIFE detects interactions between nucleic acids and proteins to identify binding, sequence and structure specificities or dissociation constants. The assay uses the Cy3 fluorophore, which increases its fluorescence in proximity to proteins. Cy3-labeled oligonucleotides are immobilised onto the bottom of a microplate well, and the basal fluorescence is measured with an appropriate microplate reader. If a protein that binds the oligonucleotide is added to the microplate well, the fluorescence will increase and can be used to report on protein-nucleic acid binding11.
For more details on a PIFE assay on BMG LABTECH microplate readers go to the application note: Protein-induced fluorescence enhancement detects protein-nucleic acid interactions in microplates.
There is a complex repertoire of DNA-protein and protein-protein interactions that control and influence biological processes, and studying these pathways further is of considerable theoretical and practical importance in understanding how cellular processes are regulated. Assays using a microplate format help to accelerate the determination of protein-nucleic acid interactions, but these assays require high sensitivity plate readers, such as the CLARIOstar®Plus and the VANTAstarTM. These systems are equipped with everything needed for various DNA interaction assays: exceptional sensitivity to distinguish smallest differences in fluorescence, well-scan function to measure PIFE, market-leading sensitivity in fluorescence polarization and a simplified workflow as gain (with Enhanced Dynamic Range) and Z-height focus are determined automatically.
To find out more about how BMG LABTECH microplate readers can help your research on DNA interactions, have look at our molecular biology section.
Powerful and most sensitive HTS plate reader
Most flexible Plate Reader for Assay Development
Flexible microplate reader with simplified workflows
Binding constants quantify the strength of a binding reaction between a biomolecule and its target (ligand). But how do you measure them and what can you do with them?
Receptor-ligand kinetics is the study of the rates at which receptors and ligands interact, bind and dissociate. Learn why these types of measurements are important and how to measure them.
Receptor-ligand interactions are crucial for cell signalling. They are also important for drug discovery. How do microplate readers deliver benefits to both?
Gene reporter assays are sensitive and specific tools to study the regulation of gene expression. Learn about the different options available, their uses, and the benefits of running these types of assays on microplate readers.
Life in the depths of the ocean operates under extreme conditions. Find out how proteins from deep-sea luminescent organisms are useful for measurements on microplate readers.
Next generation sequencing (NGS) technologies for DNA or RNA have made tremendous progress in recent years. Find out how microplate readers can advance the quality control of nucleic acids to facilitate NGS.